


Understanding CPU Requests
In the previous post, we talked about the foundation of Kubernetes resource management. In this post, we will dive deeper into what is going on behind the scenes when we configure CPU requests to a pods containers.
apiVersion: v1
kind: Pod
metadata:
name: "frontend"
spec:
containers:
- name: "app"
image: "images.my-company.example/app:v4"
resources:
requests:
memory: "64Mi"
cpu: "250m"
limits:
memory: "128Mi"
cpu: "500m"
Resource requests are first and foremost used for scheduling decisions, but is there anything more to CPU requests?
CPU Shares
When you configure an X amount of vCPUs as a container CPU request in your pod’s manifest, Kubernetes configures (1024 * X) CPU shares for your container.
For example, if I configure 250m for my CPU requests Kubernetes will set 1024 * 250m = 256 CPU shares.
So what are CPU shares and what do they do?
To understand CPU shares, let’s talk first about the Kernel mechanism called CFS (Completely Fair Scheduler).
CFS – Completely Fair Scheduler
CFS is the default Linux CPU scheduler and is in charge of allocating CPU time between processes fairly.
The “completely fair” part is not as simple as it sounds, it actually uses a few parameters to decide what is the relative weight (priority) of each process. Many of you may be familiar with the “nice” setting that can be set for processes to change their relative weight. But currently, Kubernetes doesn’t use nice to affect the processes’ weight, instead, it configures CPU shares for a CGroup.
So, CPU shares are a Linux CGroup feature that is designed to prioritize CGroup processes for the CFS to allocate more CPU time at times of congestion to the higher priority processes.
Let me explain;
Let’s think of a single CPU timeframe (1 second for example) as a pizza. Every second a new pizza comes out of the oven, processes eat what they need from it, and then it’s gone. If all of my processes are not hungry enough to eat all the pizza in 1 second, they will eat their fill until the time is over and a new CPU-second-pizza will come out of the oven. Yummy! 🍕

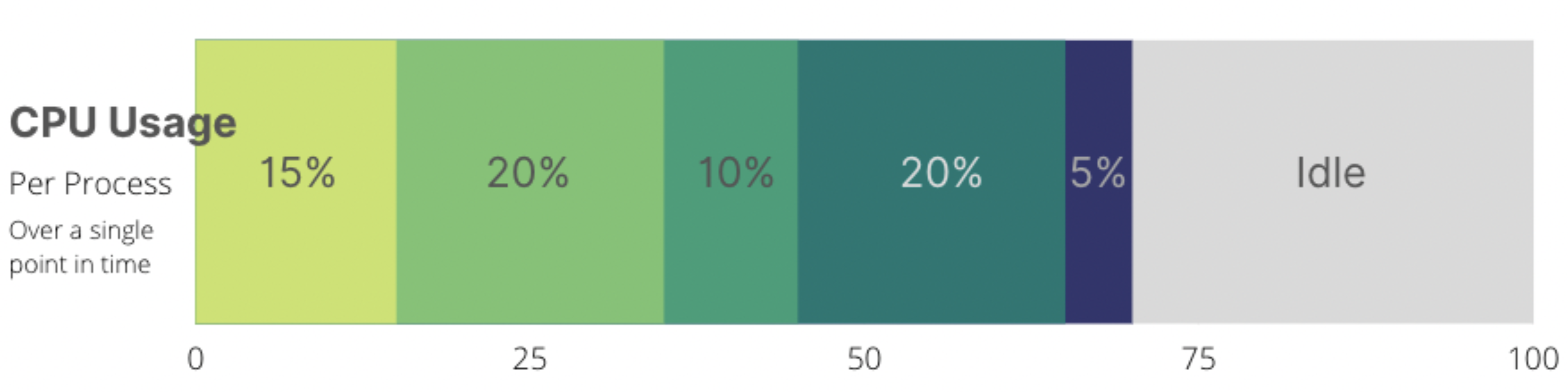 The complications start when our processes are hungry and 1 pizza every second is not enough to feed them.
The complications start when our processes are hungry and 1 pizza every second is not enough to feed them.
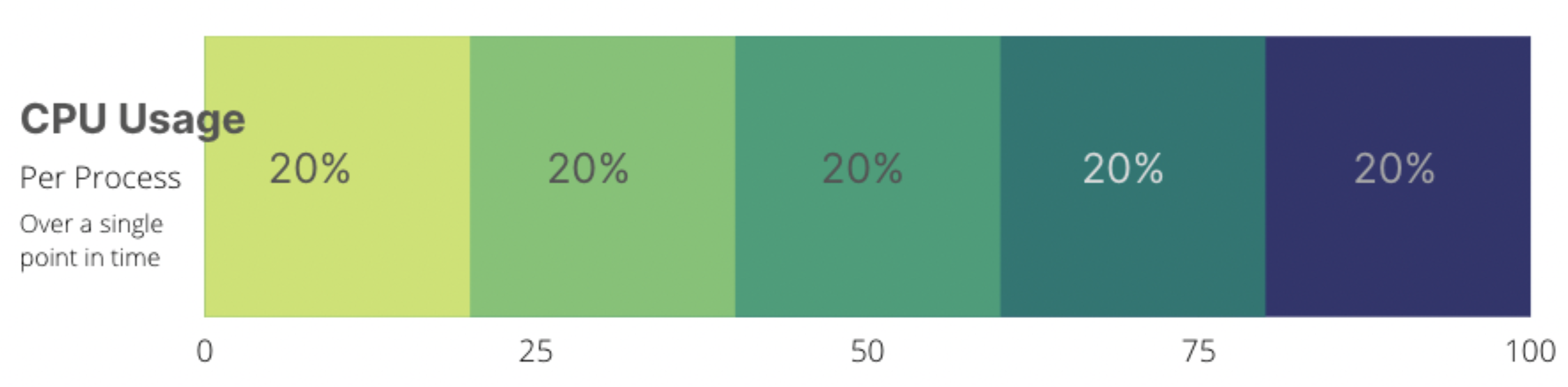 When there is not enough CPU time (or pizza) for all of my processes, CFS will look at the shares every CGroup has, will cut the pizza into the sum of all shares, and will split it accordingly.
When there is not enough CPU time (or pizza) for all of my processes, CFS will look at the shares every CGroup has, will cut the pizza into the sum of all shares, and will split it accordingly.
In the case that all the processes in the CGroup want all the CPU, the slice that each CGroup receives will be evenly distributed between the processes in that CGroup.
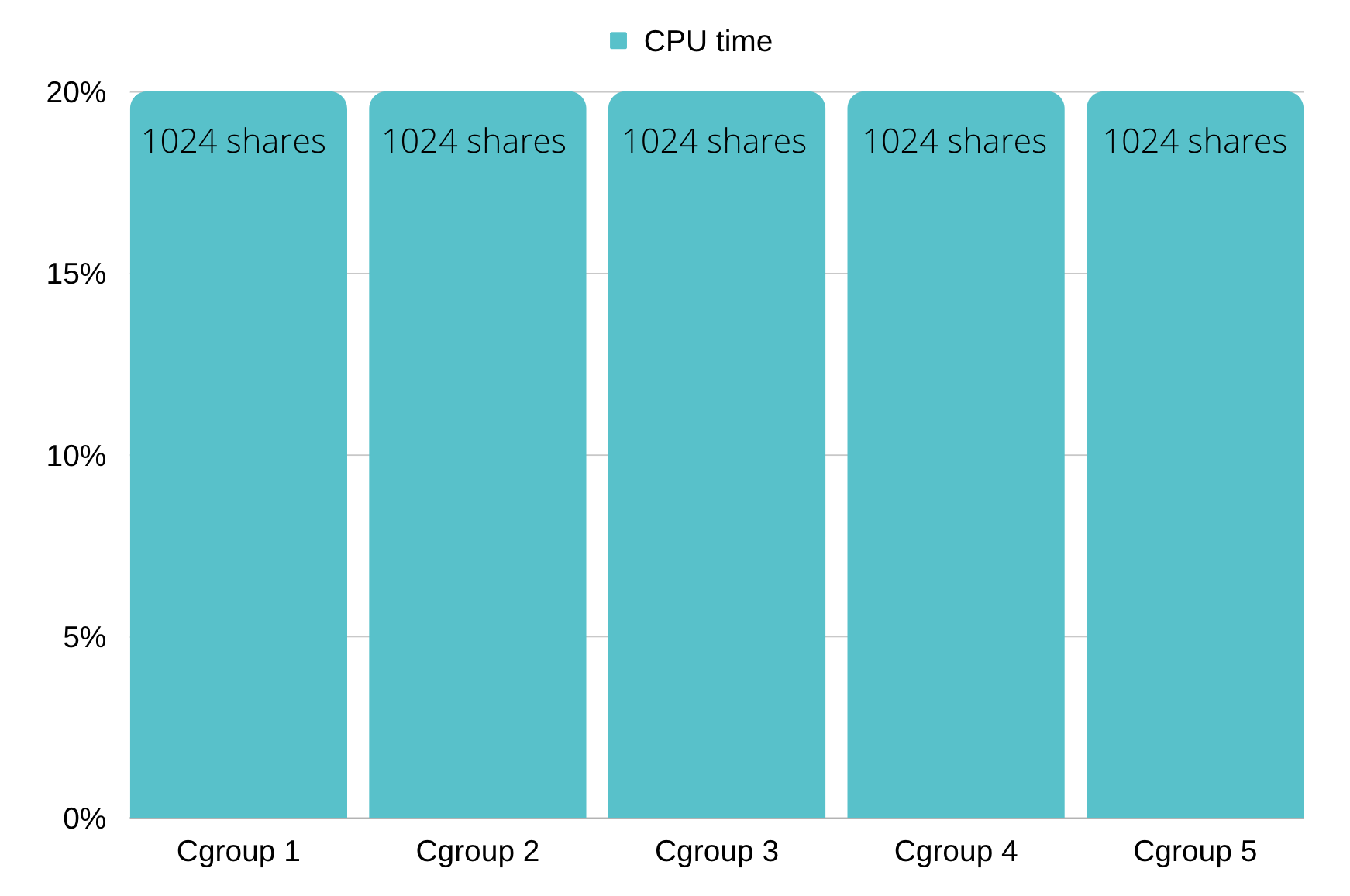
So for example, if processes if 5 CGroups are requesting the maximum amount of CPU possible, and each of the CGroups that each of them has an equal amount of CPU shares, then the CPU time will be distributed evenly between the CGroups.
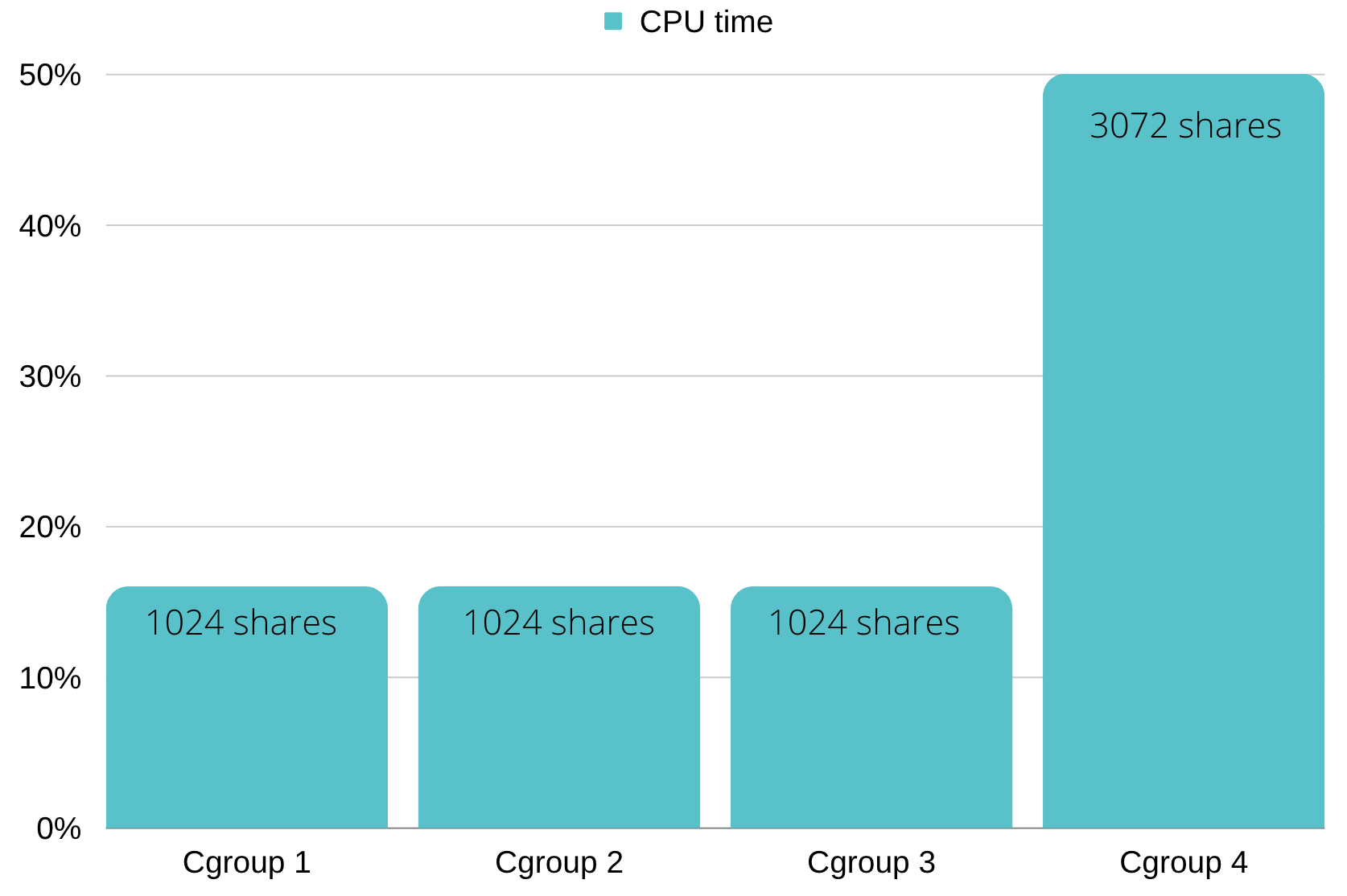
 Another example is (Staying in the state that all processes are requesting as much CPU as possible); if I have 3 CGroups with 1024 CPU shares each, and one other CGroup with 3072 shares the first 3 CGroups will get 1/6 of the CPU, and the last CGroup will get half (3/6)
Another example is (Staying in the state that all processes are requesting as much CPU as possible); if I have 3 CGroups with 1024 CPU shares each, and one other CGroup with 3072 shares the first 3 CGroups will get 1/6 of the CPU, and the last CGroup will get half (3/6)
 Remember, all of this only matters if I’m lacking CPU, if I have 3 CGroups with X CPU shares that need a lot of CPU and the fourth CGroup with 1000X CPU shares that is idle, the first 3 will split the CPU equally.
Remember, all of this only matters if I’m lacking CPU, if I have 3 CGroups with X CPU shares that need a lot of CPU and the fourth CGroup with 1000X CPU shares that is idle, the first 3 will split the CPU equally.
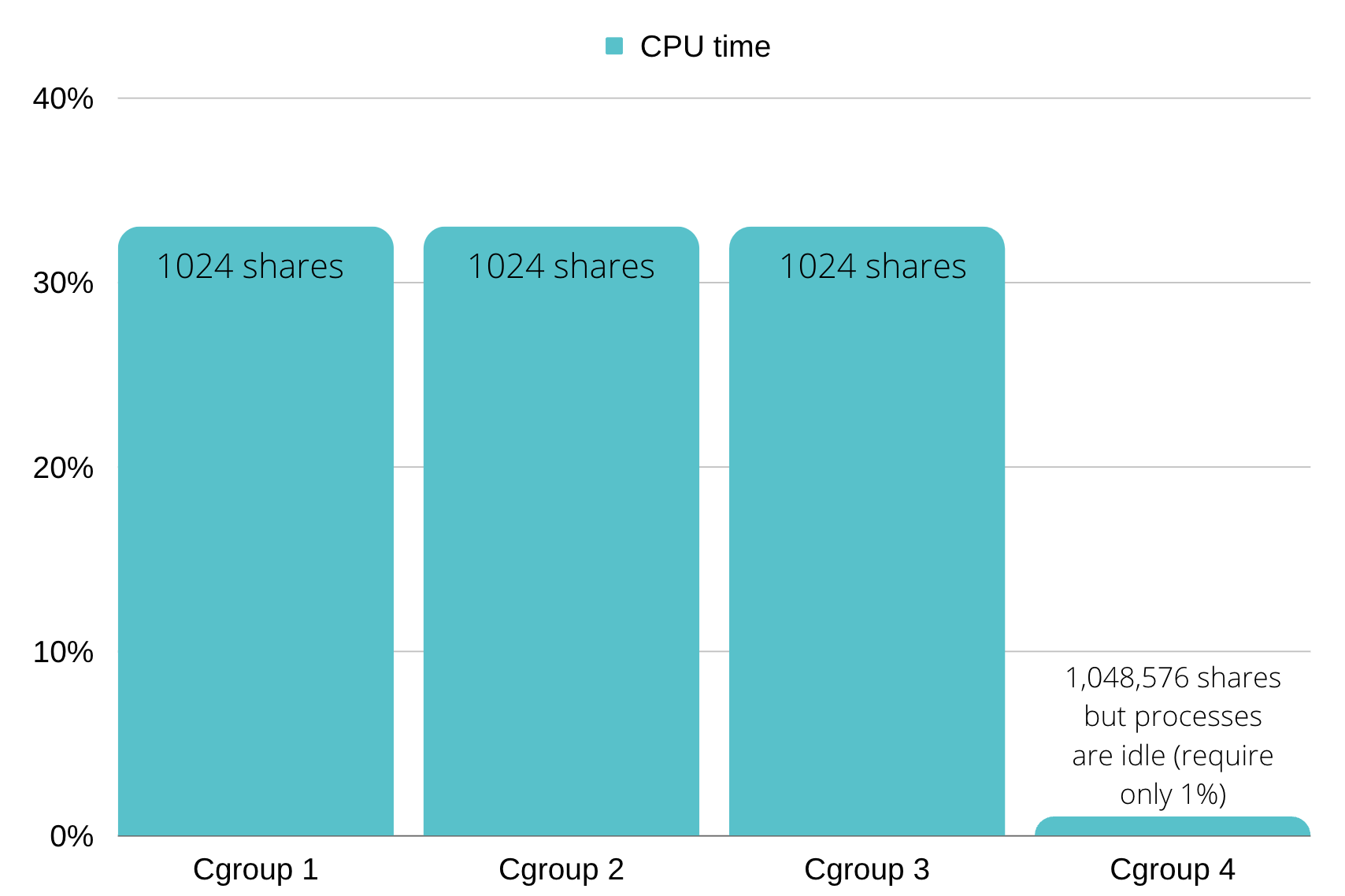
Can my container even have 1,048,576 CPU shares on Kubernetes? Only if my node has more than 1024 CPU cores such as the Epiphany-V, but I’m sure most of us don’t have those kinds of nodes.
How Kubernetes uses these features
So as we’ve said, Kubernetes CPU requests configure CPU shares for our containers CGroups,
Shares “over-commitment” is prevented by Kubernetes magic; On one hand, the scheduler only schedules on each node the total amount of CPU requests to be lower or equal to the amount of CPU on the node (allocatable – see previous part). On the other hand, the CPU shares you provision can be up to 1024 times the number of cores. That sets a cap on the maximum number of shares that can be used by the pods, and the ratio remains.
The sum of CPU shares your containers can have on Kubernetes is 1024 times the number of allocatable CPUs you have in your cluster.
Real-life examples
We have tried to make the previous examples as simple as possible so I removed some important parameters such as:
- Threads and processes count in each CGroup
- The CPU consumed by the node (other than your running pods)
- Pod priority
- Evictions?
To mention a few,
Let’s have a shallow dive into them;
Thread Count
When we run just a single process in our container, if that process only creates a single thread, it can not consume more than one core anyway. When you set CPU requests to your containers, always bear in mind the number of threads they will run.
A side note – threads are not free, try not to use too many threads as each thread brings its own overhead, and increase the number of replicas instead.
Node Load
The bar charts from earlier are for isolated processes, but not all processes are isolated. Not to worry! The CGroups for your containers are pretty low on the CGroups hierarchy.
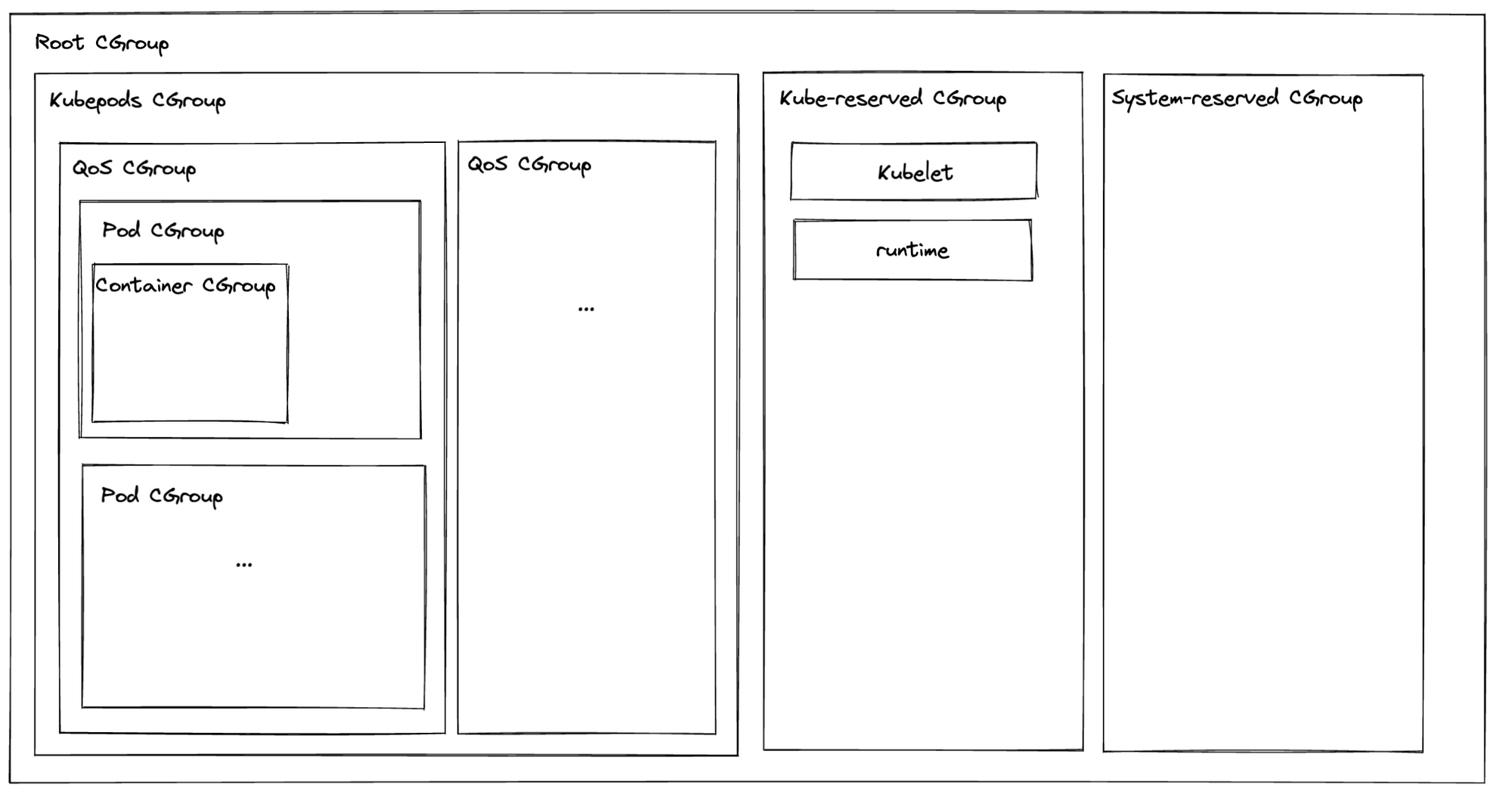
Maybe while reading you already went to check how many CPU shares your Kubelet has to make sure it’s not deprived. Don’t worry, Your pods and containers are just sharing the CPU time “kubepods” CGroup is eligible for. If the Kubelet, the container runtime, or other services on the node need CPU time, they will get it.
Don’t worry when setting high CPU requests, the node’s components are higher priority out of the box.
Quality of Service
Kubernetes is configuring CGroups per QoS, currently, they have no real function and they exist for future use.
In terms of CPU time and priority, the CPU Requests is the only thing that matters.
So what will happen if you don’t set CPU Requests? The container will get 2 CPU shares by default and will have a very low priority compared to pods that have CPU requests configured.
Pod Priority
“It’s OK, I set pod priority.” – Sorry but not exactly…
Pod priority is only used to determine the termination order on node evection, and as we’ve mentioned; There is no eviction caused by CPU pressure.
Evictions
Eviction is a process running on the node that chooses and kills pods when the node is low on resources. Eviction only happens for in-compressible resources like memory, disk space, etc. more on that in the fourth part.
Not just for scheduling
We learned that CPU requests are used not only for scheduling purposes but also for the lifetime of the container. Memory requests also have their deep layers, more on that in part four.
Also, we talked only about normal Kubernetes behavior, there are many other options like CPU pinning that sets exclusive CPU cores per container. That’s outside of the scope of this article, but we may get into it in the future 😄
To summarize;
We got into what configuring CPU requests affect behind the scenes and exactly how it all functions. We also talked about other real-life aspects that may have been relevant and that aren’t really…
Stay tuned for part 3, where we will talk all about CPU limits and why setting them may even hurt your workloads.